
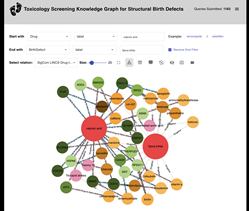
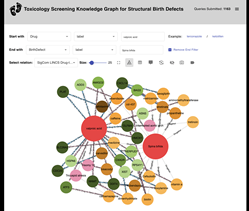
To provide access to the data used to create the new AI model, the researchers developed a website that enables users to explore relationships between genes, drugs, and birth defects.
NEW YORK (PRWEB)
July 17, 2023
Data scientists at the Icahn School of Medicine at Mount Sinai in New York and colleagues have created an artificial intelligence model that may more accurately predict which existing medicines, not currently classified as harmful, may in fact lead to congenital disabilities.
The model, or “knowledge graph,” described in the July 17 issue of the Nature journal Communications Medicine [DOI: 10.1038/s43856-023-00329-2], also has the potential to predict the involvement of pre-clinical compounds that may harm the developing fetus. The study is the first known of its kind to use knowledge graphs to integrate various data types to investigate the causes of congenital disabilities.
Birth defects are abnormalities that affect about 1 in 33 births in the United States. They can be functional or structural and are believed to result from various factors, including genetics. However, the causes of most of these disabilities remain unknown. Certain substances found in medicines, cosmetics, food, and environmental pollutants can potentially lead to birth defects if exposed during pregnancy.
“We wanted to improve our understanding of reproductive health and fetal development, and importantly, warn about the potential of new drugs to cause birth defects before these drugs are widely marketed and distributed,” says Avi Ma’ayan, PhD, Professor, Pharmacological Sciences, and Director of the Mount Sinai Center for Bioinformatics at Icahn Mount Sinai, and senior author of the paper. “Although identifying the underlying causes is a complicated task, we offer hope that through complex data analysis like this that integrates evidence from multiple sources, we will be able, in some cases, to better predict, regulate, and protect against the significant harm that congenital disabilities could cause.”
The researchers gathered knowledge across several datasets on birth-defect associations noted in published work, including those produced by NIH Common Fund programs, to demonstrate how integrating data from these resources can lead to synergistic discoveries. Particularly, the combined data is from the known genetics of reproductive health, classification of medicines based on their risk during pregnancy, and how drugs and pre-clinical compounds affect the biological mechanisms inside human cells.
Specifically, the data included studies on genetic associations, drug- and preclinical-compound-induced gene expression changes in cell lines, known drug targets, genetic burden scores for human genes, and placental crossing scores for small molecule drugs.
Importantly, using ReproTox-KG, with semi-supervised learning (SSL), the research team prioritized 30,000 preclinical small molecule drugs for their potential to cross the placenta and induce birth defects. SSL is a branch of machine learning that uses a small amount of labeled data to guide predictions for much larger unlabeled data. In addition, by analyzing the topology of the ReproTox-KG more than 500 birth-defect/gene/drug cliques were identified that could explain molecular mechanisms that underlie drug-induced birth defects. In graph theory terms, cliques are subsets of a graph where all the nodes in the clique are directly connected to all other nodes in the clique.
Share article on social media or email: